Deep Learning
Posted on
This note is based on LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
Abstract
- computational model that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction
- applications: speech recognition, visual object recognition, object detection, drug discovery and genomics
- discovers intricate structure in large data sets by using the backpropagation algorithm to indicate a machine should change its internal parameters that are used to compute the representation in each layer from the representation in the previous layer.
- deep convolutional nets in processing images, video, speech and audio, while recurrent nets in sequential data such as text and speech.
Introduction
- conventional machine-learning techniques were limited in their ability to process natural data in their raw form
- representation learning is a set of methods that allows a machine to be fed with raw data and to automatically discover the representations needed for detection or classification.
- deep-learning methods are representation-learning methods with multiple levels of representation, obtained by composing simple but non-linear modules that each transform the representation at one level into a representation at a higher, slightly more abstract level.
- for classification tasks, higher layers of representation amplify aspects of the input that are important for discrimination and suppress irrelevant variations.
The example of an image
- the learned features in the first layer of representation typically represent the presence or absence of edges at particular orientations and locations in the image
- the second layer typically detects motifs by spotting particular arrangements of edges, regardless of small variations in the edge positions.
- the third layer may assemble motifs into larger combinations that correspond to parts of familiar objects
The key aspect of deep learning is that these layers of features are not designed by human engineers: they are learned from data using a general-purpose learning procedure.
Success
- image recognition and speech recognition
- predicting the activity of potential drug molecules
- analysing particle accelerator data
- reconstructing brain circuits
- predicting the effect of mutations in non-coding DNA on gene expression and disease
- natural language understanding, particularly topic classification, sentiment analysis, question answering and language translation
Supervised learning
- gradient descent
- stochastic gradient descent (SGD): showing the input vector for a few examples, computing the outputs and the errors, computing the average gradient for these examples, and adjusting the weights accordingly. It is called stochastic because each small set of examples gives a noisy estimate of the average gradient over all examples.
- a deep-learning architecture is a multilayer stack of simple modules, all (or most) of which are subjects to learning, and many of which compute non-linear input-output mappings. Each module in the stack transforms its input to increase both the selectivity and the invariance of the representation.
Backpropagation to train multilayer architectures
- The backpropagation equation can be applied repeatedly to propagate gradients through all modules, starting from the output at the top (where the network procedures its prediction) all the way to the bottom (where the external input is fed).
- At present, the most popular non-linear function is the rectified linear unit (ReLU), which is simply the half-wave rectifier $f(z)=\max(z,0)$. In past decades, neural nets used smoother non-linearities, such as $\tanh(z)$ or $1/(1+\exp(-z))$, but the ReLU typically learns much faster in networks with many layers, allowing training of a deep supervised network without unsupervised pre-training.
- Recent theoretical and empirical results strongly suggest that local minima are not a serious issue in general.
Convolutional neural networks
One particular type of deep, feedforward network that was much easier to train and generalized much better than networks with full connectivity between adjacent layers.
ConvNets are designed to process data that come in the form of multiple arrays, for example, a colour image composed of three 2D arrays containing pixel intensities in the three colour channels.
Four key ideas behind ConvNets that take advantage of the properties of natural signals:
- local connections
- shared weights
- pooling and the use of many layers.
The architecture of a typical ConvNet is structured as a series of stages.
- The first few stages are composed of two types of layers: conventional layers and pooling layers.
- Units in a convolutional layer are organized in feature maps, within which each unit is connected to local patches in the feature maps of the previous layer through a set of weights called a filter bank.
Image understanding with deep convolutional networks
In the ImageNet competition 2012, when deep convolutional networks were applied to a data set of about a million images from the web that contained 1000 different classes, they achieved spectacular results, almost halving the error rates of the best competing approaches. This success came from the efficient use of GPUs, ReLUs, a new regularization technique called dropout. This success has brought about a revolution in computer vision; ConvNets are now the dominant approach for almost all recognition and detection tasks.
Distributed representations and language processing
Deep-learning theory shows that deep nets have two different exponential advantages over classic learning algorithms that do not use distributed representations.
- learning distributed representations enable generalization to new combinations of the values of learned features beyond those seen during training
- composing layers of representation in a deep net brings the potential for another exponential advantage.
Recurrent neural networks
For tasks that involve sequential inputs, such as speech and language, it is often better to sequential inputs, such as speech and language, it is often better to use RNNs.
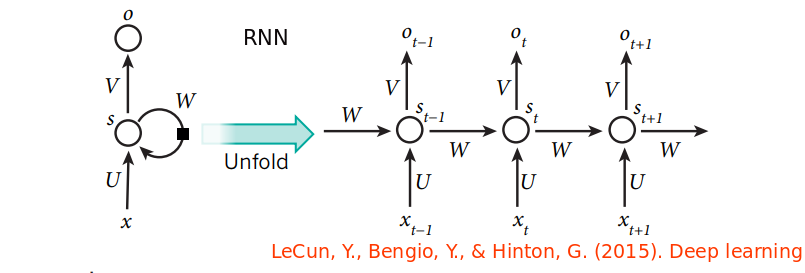
Thanks to advances in their architecture and ways of training them, RNNs have been found to be very good at predicting the next character in the text or the next word in a sequence, but they can also be used for more complex tasks.
The long short-term memory (LSTM) networks that use special hidden units, the natural behavior of which is to remember inputs for a long time to augment the network with an explicit memory.
Memory networks can be trained to keep track of the state of the world in a setting similar to a text adventure game and after reading a story, they can answer questions that require complex inference.
The future of deep learning
Human and animal learning is largely unsupervised: we discover the structure of the world by observing it, not by being told the name of every object.
Combine ConvNets with RNNs that use reinforcement learning to decide where to look.
Major processes in AI will come about through systems that combine representation learning with complex reasoning.