July 28, 2026
This note is for Hines, Oliver J., Karla Diaz-Ordaz, and Stijn Vansteelandt. “Variable Importance Measures for Heterogeneous Treatment Effects.” Biometrics 81, no. 4 (2025): ujaf140.
Continue reading
July 18, 2026
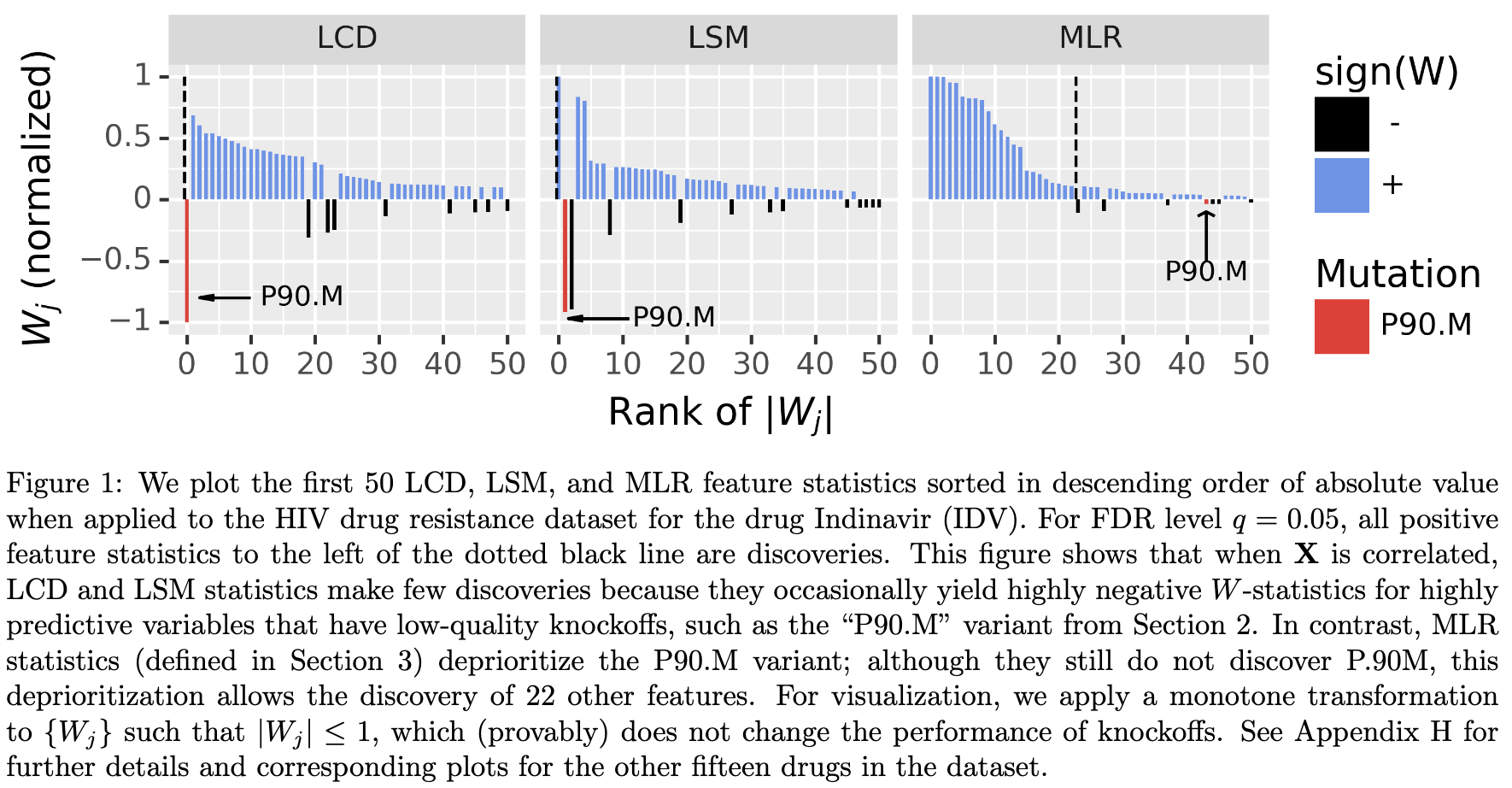
This note is for Spector, Asher, and William Fithian. “Asymptotically Optimal Knockoff Statistics via the Masked Likelihood Ratio.” arXiv:2212.08766. Preprint, arXiv, October 1, 2024.
Continue reading
July 18, 2026
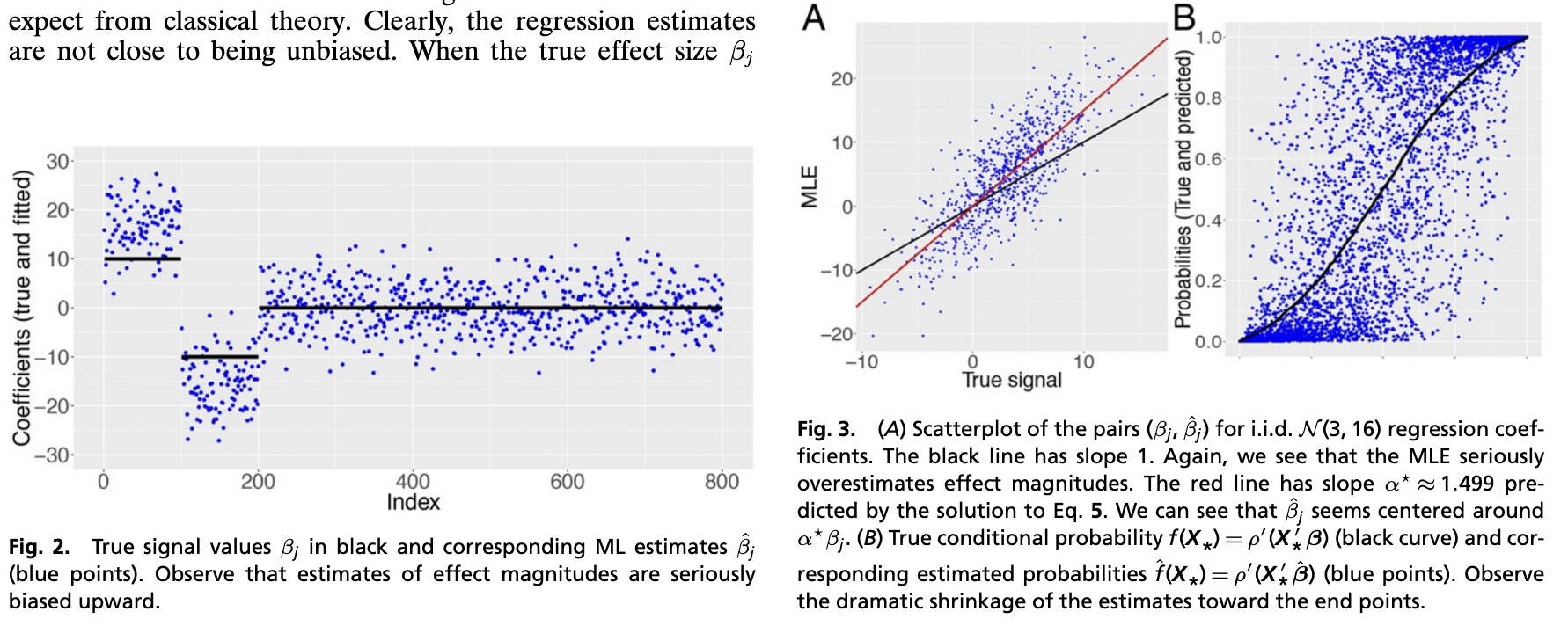
This is the note for Sur, Pragya, and Emmanuel J. Candès. “A Modern Maximum-Likelihood Theory for High-Dimensional Logistic Regression.” Proceedings of the National Academy of Sciences 116, no. 29 (2019): 14516–25.
Continue reading
June 10, 2026
This note is for Polson, N. G., Scott, J. G., & Windle, J. (2013). Bayesian Inference for Logistic Models Using Pólya–Gamma Latent Variables. Journal of the American Statistical Association, 108(504), 1339–1349.
Continue reading
May 14, 2026
This note is for Lacroix, P., & Martin, M.-L. (2024). Trade-off between predictive performance and FDR control for high-dimensional Gaussian model selection. Electronic Journal of Statistics, 18(2).
Continue reading
May 01, 2026 (Update: )
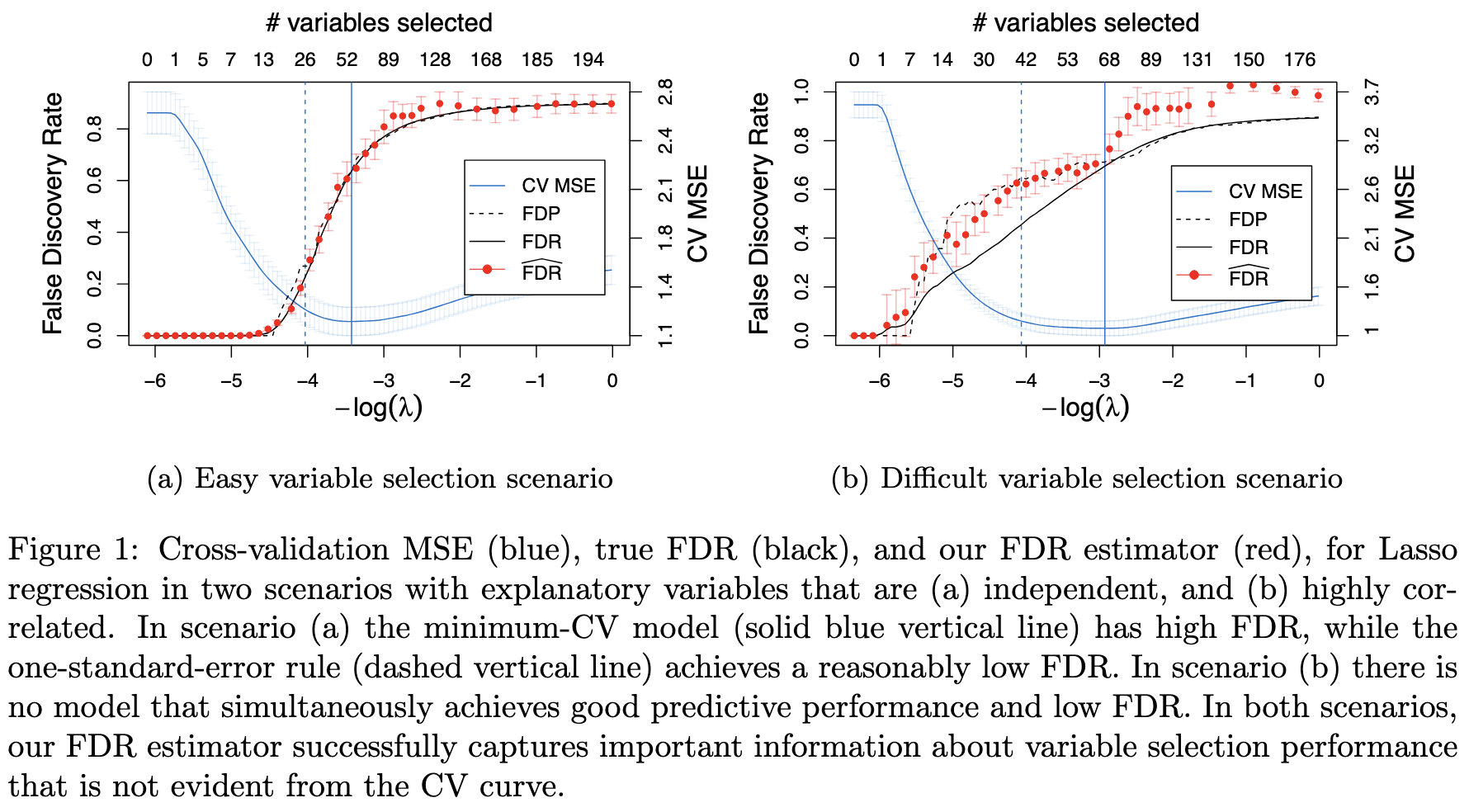
This note is for Luo, Yixiang, William Fithian, and Lihua Lei. “Estimating the FDR of Variable Selection.” arXiv:2408.07231. Preprint, arXiv, August 17, 2024.
Continue reading
April 29, 2026 (Update: )

This note is for Ren, Z., & Candès, E. (2023). Knockoffs with side information. The Annals of Applied Statistics, 17(2), 1152–1174.
Continue reading
April 05, 2026
This note is for Chakraborty, Abhinav, Junu Lee, and Eugene Katsevich. “Power of Masking Methods for Adaptive Testing in a Multivariate Normal Means Problem.” arXiv:2601.07764. Version 2. Preprint, arXiv, March 31, 2026..
Continue reading
April 05, 2026
This note is for Yang, Chiao-Yu, Lihua Lei, Nhat Ho, and Will Fithian. “BONuS: Multiple Multivariate Testing with a Data-Adaptive test Statistic.” arXiv:2106.15743. Preprint, arXiv, July 1, 2021.
Continue reading
April 01, 2026
This note is for Candès, E., Lei, L., & Ren, Z. (2023). Conformalized survival analysis. Journal of the Royal Statistical Society Series B: Statistical Methodology, 85(1), 24–45.
Continue reading
February 28, 2026
This note is for Ke, Zheng Tracy, Jun S. Liu, and Yucong Ma. “Power of Knockoff: The Impact of Ranking Algorithm, Augmented Design, and Symmetric Statistic.” arXiv:2010.08132. Preprint, arXiv, February 13, 2024.
Continue reading
January 19, 2026
This note is for Duan, T., Anand, A., Ding, D. Y., Thai, K. K., Basu, S., Ng, A., & Schuler, A. (2020). NGBoost: Natural Gradient Boosting for Probabilistic Prediction. Proceedings of the 37th International Conference on Machine Learning, 2690–2700.
Continue reading
January 07, 2026
This note is for McInnes, L., Healy, J., & Melville, J. (2020). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction (No. arXiv:1802.03426). arXiv.
Continue reading
December 29, 2025
This note is for Lei, J. (2020). Cross-Validation With Confidence. Journal of the American Statistical Association, 115(532), 1978–1997.
Continue reading
November 12, 2025
This note is for Barnett, I., Mukherjee, R., & Lin, X. (2017). The Generalized Higher Criticism for Testing SNP-Set Effects in Genetic Association Studies. Journal of the American Statistical Association, 112(517), 64–76.
Continue reading
October 25, 2025
This note is for Liu, K., Long, Q., Shi, Z., Su, W. J., & Xiao, J. (2025). Statistical Impossibility and Possibility of Aligning LLMs with Human Preferences: From Condorcet Paradox to Nash Equilibrium (No. arXiv:2503.10990). arXiv.
Continue reading
October 22, 2025
This note is for Zrnic, T., & Candès, E. J. (2024). Cross-prediction-powered inference. Proceedings of the National Academy of Sciences, 121(15), e2322083121.
Continue reading
October 16, 2025
This note is for Wu, R., Zhou, S., Lu, J., Shen, Z., Xu, Z., Shu, J., Yang, K., Lin, F., & Zhang, Y. (2024). Removing obstacles before breaking through the memory wall: A close look at HBM errors in the field. Proceedings of the 2024 USENIX Conference on Usenix Annual Technical Conference, 851–867.
Continue reading
October 16, 2025
This note is for Yu, Q., Zhang, W., Cardoso, J., & Kao, O. (2023). Exploring Error Bits for Memory Failure Prediction: An In-Depth Correlative Study. 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), 01–09.
Continue reading
October 15, 2025
This note is for Donoho, D., & Jin, J. (2004). Higher criticism for detecting sparse heterogeneous mixtures. The Annals of Statistics, 32(3), 962–994.
Continue reading
October 11, 2025
This note is for Kim, M. P., Ghorbani, A., & Zou, J. (2018). Multiaccuracy: Black-Box Post-Processing for Fairness in Classification (No. arXiv:1805.12317). arXiv.
Continue reading
October 10, 2025
This note is for Wright, I. W., & Wegman, E. J. (1980). Isotonic, Convex and Related Splines. The Annals of Statistics, 8(5), 1023–1035.
Continue reading
October 08, 2025
This note is for Deng, Z., Zhang, J., Zhang, L., Ye, T., Coley, Y., Su, W. J., & Zou, J. (2022). FIFA: Making Fairness More Generalizable in Classifiers Trained on Imbalanced Data (No. arXiv:2206.02792). arXiv.
Continue reading
October 06, 2025
This note is for Zhang, L., Roth, A., & Zhang, L. (2024). Fair Risk Control: A Generalized Framework for Calibrating Multi-group Fairness Risks. Proceedings of the 41st International Conference on Machine Learning, 59783–59805.
Continue reading
October 05, 2025
This note is for Li, X., Ruan, F., Wang, H., Long, Q., & Su, W. J. (2025). Robust detection of watermarks for large language models under human edits. Journal of the Royal Statistical Society Series B.
Continue reading
October 04, 2025
This note is for Viladomat, J., Mazumder, R., McInturff, A., McCauley, D. J., & Hastie, T. (2014). Assessing the significance of global and local correlations under spatial autocorrelation: A nonparametric approach. Biometrics, 70(2), 409–418.
Continue reading
October 03, 2025

This note is for Wang, Y., Zang, C., Li, Z., Guo, C. C., Lai, D., & Wei, P. (2025). A comparative study of statistical methods for identifying differentially expressed genes in spatial transcriptomics (p. 2025.02.17.638726). bioRxiv.
Continue reading
October 03, 2025
This note is for Xie, Y., Li, X., Mallick, T., Su, W., & Zhang, R. (2025). Debiasing Watermarks for Large Language Models via Maximal Coupling. Journal of the American Statistical Association, 0(0), 1–11.
Continue reading
October 02, 2025
This note is for the paper Zrnic, T., & Jordan, M. I. (2023). Post-selection inference via algorithmic stability. The Annals of Statistics, 51(4), 1666–1691..
Continue reading
September 04, 2025 (Update: )
This note is for Jain, A., Montanari, A., & Sasoglu, E. (2024, November 6). Scaling laws for learning with real and surrogate data. The Thirty-eighth Annual Conference on Neural Information Processing Systems.
Continue reading
July 22, 2025
this note is for Tian, X., & Shen, X. (2025). Enhancing Accuracy in Generative Models via Knowledge Transfer (No. arXiv:2405.16837). arXiv.
Continue reading
June 12, 2025
This note is for Tang, D., Kong, D., & Wang, L. (2024). The synthetic instrument: From sparse association to sparse causation (No. arXiv:2304.01098). arXiv.
Continue reading
June 02, 2025
This note is for Miao, W., Hu ,Wenjie, Ogburn ,Elizabeth L., & and Zhou, X.-H. (2023). Identifying Effects of Multiple Treatments in the Presence of Unmeasured Confounding. Journal of the American Statistical Association, 118(543), 1953–1967.
Continue reading
May 01, 2025
This note is for Laves, M.-H., Ihler, S., Fast, J. F., Kahrs, L. A., & Ortmaier, T. (2020). Well-Calibrated Regression Uncertainty in Medical Imaging with Deep Learning. Proceedings of the Third Conference on Medical Imaging with Deep Learning, 393–412.
Continue reading
April 25, 2025
This is the note for Lahlou, S., Jain, M., Nekoei, H., Butoi, V. I., Bertin, P., Rector-Brooks, J., Korablyov, M., & Bengio, Y. (2023). DEUP: Direct Epistemic Uncertainty Prediction (No. arXiv:2102.08501). arXiv. https://doi.org/10.48550/arXiv.2102.08501
Continue reading
April 23, 2025
This note is for Upadhyay, U., Kim, J. M., Schmidt, C., Schölkopf, B., & Akata, Z. (2023). Likelihood Annealing: Fast Calibrated Uncertainty for Regression (No. arXiv:2302.11012). arXiv. https://doi.org/10.48550/arXiv.2302.11012
Continue reading
April 23, 2025
This note is for Cherian, J., Gibbs, I., & Candes, E. (2024, November 6). Large language model validity via enhanced conformal prediction methods. The Thirty-eighth Annual Conference on Neural Information Processing Systems.
Continue reading
April 21, 2025
This note is for Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R., & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631(8022), 755–759. https://doi.org/10.1038/s41586-024-07566-y
Continue reading
April 09, 2025
This note is for Liu, Y., & and Xie, J. (2020). Cauchy Combination Test: A Powerful Test With Analytic p-Value Calculation Under Arbitrary Dependency Structures. Journal of the American Statistical Association, 115(529), 393–402.
Continue reading
April 05, 2025
This note is for Kotelnikov, A., Baranchuk, D., Rubachev, I., & Babenko, A. (2023). TabDDPM: Modelling Tabular Data with Diffusion Models. Proceedings of the 40th International Conference on Machine Learning, 17564–17579.
Continue reading
February 23, 2025
This note is for Leng, Z., Tan, M., Liu, C., Cubuk, E. D., Shi, X., Cheng, S., & Anguelov, D. (2022). PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions (No. arXiv:2204.12511). arXiv. https://doi.org/10.48550/arXiv.2204.12511
Continue reading
February 23, 2025
This note is for Pereyra, G., Tucker, G., Chorowski, J., Kaiser, Ł., & Hinton, G. (2017). Regularizing Neural Networks by Penalizing Confident Output Distributions (No. arXiv:1701.06548). arXiv. https://doi.org/10.48550/arXiv.1701.06548
Continue reading
February 22, 2025
This note is for Müller, R., Kornblith, S., & Hinton, G. E. (2019). When does label smoothing help? Advances in Neural Information Processing Systems, 32.
Continue reading
February 22, 2025
This post is for Mukhoti, J., Kulharia, V., Sanyal, A., Golodetz, S., Torr, P., & Dokania, P. (2020). Calibrating Deep Neural Networks using Focal Loss. Advances in Neural Information Processing Systems, 33, 15288–15299.
Continue reading
February 11, 2025
This note is for Wang, H., Ibrahim, S., & Mazumder, R. (2023). Nonparametric Finite Mixture Models with Possible Shape Constraints: A Cubic Newton Approach (No. arXiv:2107.08535). arXiv. https://doi.org/10.48550/arXiv.2107.08535
Continue reading
February 07, 2025
This note is for Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Candès, E., & Hashimoto, T. (2025). s1: Simple test-time scaling (No. arXiv:2501.19393). arXiv. https://doi.org/10.48550/arXiv.2501.19393
Continue reading
February 07, 2025
This note is based on Hershey, J. R., & Olsen, P. A. (2007). Approximating the Kullback Leibler Divergence Between Gaussian Mixture Models. 2007 IEEE International Conference on Acoustics, Speech and Signal Processing - ICASSP ’07, 4, IV-317-IV–320. https://doi.org/10.1109/ICASSP.2007.366913
Continue reading
February 06, 2025
This post is for Cai, T. T., Ma, J., & Zhang, L. (2019). CHIME: Clustering of high-dimensional Gaussian mixtures with EM algorithm and its optimality. The Annals of Statistics, 47(3), 1234–1267. https://doi.org/10.1214/18-AOS1711
Continue reading
February 06, 2025
This note is for Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. (2017). Variational Inference: A Review for Statisticians. Journal of the American Statistical Association, 112(518), 859–877. https://doi.org/10.1080/01621459.2017.1285773
Continue reading
February 04, 2025
This post is for Dwivedi, R., Ho, N., Khamaru, K., Wainwright, M. J., Jordan, M. I., & Yu, B. (2020). Singularity, Misspecification and the Convergence Rate of Em. The Annals of Statistics, 48(6), 3161–3182.
Continue reading
See all posts →