Word Segmentation and Medical Concept Recognition for Chinese Medical Texts
Posted on
Two fundamental tasks to process Chinese electronic medical records (EMRs):
- Chinese word segmentation
- medical concept recognition: it assigns an EMR-related tag (e.g., organism and group) to the segmented words.
Challenge:
- lack of medical domain datasets with high-quality annotations
- the models trained in the general domain always fail to have good performance
The paper:
- collect a Chinese EMR corpus (ACEMR), where texts from 500 EMRs (7K sentences) with human annotations for Chinese word segmentation and EMR-related tags
- run well-known models (i.e., BiLSTM, BERT and ZEN) and existing state-of-art systems (e.g., WMSeg and TwASP) for CWS and medical concept recognition
- experiments demonstrate that the necessity of building a dedicated medical dataset and show that models that leverage extra resources achieve the best performance for both tasks
Related work
Due to the dramatic performance drop when applying the model trained from open source corpus on the medical field, previous studies always construct Chinese medical datasets themselves and test their models on the datasets.
However, most constructed datasets used for CWS are relatively small, only roughly 100 Chinese EMRs.
Besides, the medical concept types in most existing datasets are limited to named entities (e.g. “Disease” and “Symptoms and Signs”), which fails to consider other medical concept types (e.g. “Time”)
Annotated Chinese Electronic Medical Record (ACEMR) Corpus
Data Collection
collect 500 Chinese EMRs from five departments of a local hospital, where one EMR specifically means the First Course Record in the inpatient record.
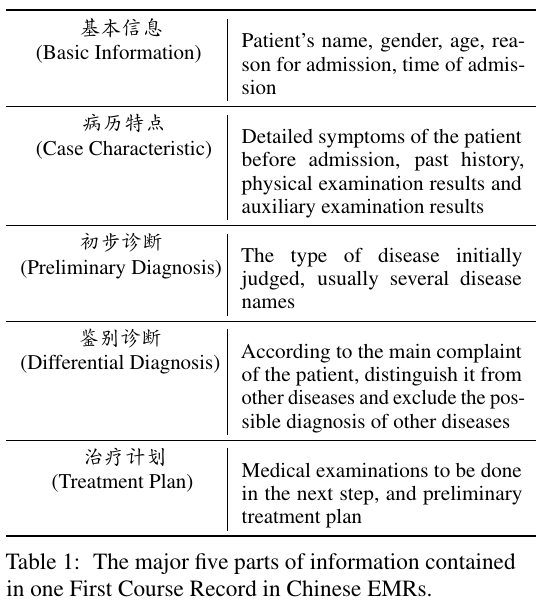
CWS and Medical Concept Annotation
Four specialists participated in the development of the annotation guideline.
- CWS: the segmentation guidelines of the Chinese Treebank (Xia, 2000) for the general domain as well as the annotation guideline proposed by He et al. (2017) for the medical domain.
- medical concept: the medical taxonomy defined by unified medical language system (UMLS) semantic groups (Lindberg et al., 1993) and define 7 major medical concept classes with 20 sub-classes.

an example

Experiments
